Principio de responsabilidad única
De todos los principios SOLID, el Principio de Responsabilidad Única (SRP) podría ser el menos comprendido. Probablemente se debe a que tiene un nombre particularmente inapropiado. Es demasiado fácil para los programadores escuchar el nombre y asumir que significa que cada módulo debería hacer solo una cosa.
No nos equivoquemos, existe un principio así. Una función debe hacer una, y solo una, cosa. Usamos ese principio cuando refactorizamos funciones grandes en funciones más pequeñas; lo usamos en los niveles más bajos. Pero no es uno de los principios SOLID, no es el SRP.
Históricamente, el SRP se ha descrito de esta manera:
Un módulo debe tener una, y solo una, razón para cambiar.
Los sistemas de software se cambian para satisfacer a los usuarios y partes interesadas; esos usuarios y partes interesadas son la “razón para cambiar” de la que habla el principio.
De hecho, podemos reformular el principio para decir esto:
Un módulo debe ser responsable ante uno, y solo uno, usuario o parte interesada.
Desafortunadamente, las palabras “usuario” y “parte interesada” no son realmente las palabras correctas para usar aquí. Es probable que haya más de un usuario o parte interesada que quiera que el sistema cambie de la misma manera. En cambio, nos referimos realmente a un grupo: una o más personas que requieren ese cambio. Nos referiremos a ese grupo como un actor.
Así, la versión final del SRP es:
Un módulo debe ser responsable ante uno, y solo un, actor.
Ahora, ¿qué queremos decir con la palabra “módulo”? La definición más simple es simplemente un archivo fuente. Para nuestro curso, esto se refiere a una clase. La mayoría de las veces, esa definición funciona bien. Sin embargo, algunos lenguajes y entornos de desarrollo no usan archivos fuente para contener su código. En esos casos, un módulo es simplemente un conjunto cohesivo de funciones y estructuras de datos.
Esa palabra “cohesivo” implica el SRP. La cohesión es la fuerza que une el código responsable ante un solo actor.
Quizás la mejor manera de entender este principio sea observando los síntomas de violarlo.
SÍNTOMA 1: DUPLICACIÓN ACCIDENTAL
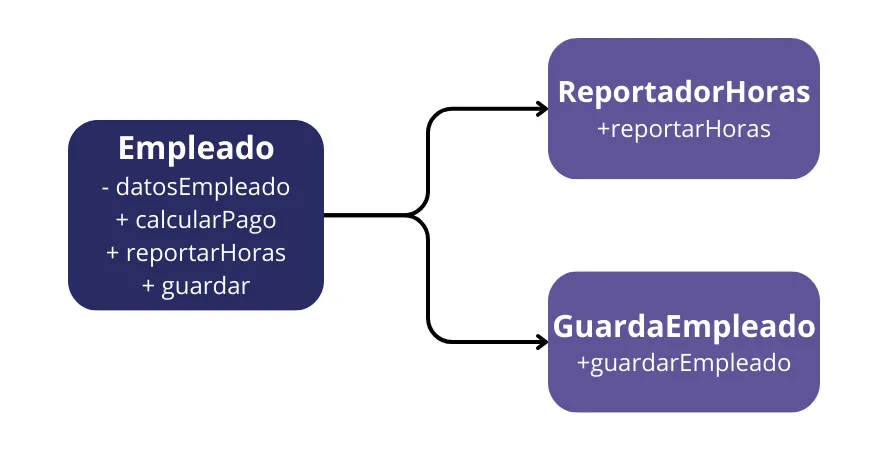
Un claro ejemplo es la clase Empleado de una aplicación de nómina. Esta tiene tres métodos: calcularPago(), reportarHoras() y guardar().
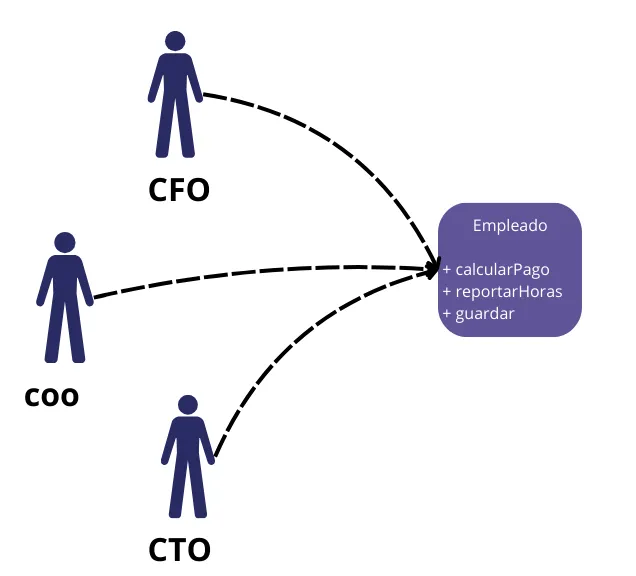
Esta clase viola el SRP porque esos tres métodos son responsables ante tres actores muy diferentes.
-
El método
calcularPago()es especificado por el departamento de contabilidad, que reporta al Director Financiero. -
El método
reportarHoras()es especificado y utilizado por el departamento de recursos humanos, que reporta al Director de Operaciones. -
El método
guardar()es especificado por los administradores de bases de datos (DBAs), que reportan alDirector de Tecnología.
Al poner el código fuente de estos tres métodos en una sola clase Empleado, los desarrolladores han acoplado a cada uno de estos actores con los otros. Este acoplamiento puede hacer que las acciones del equipo del Director Financiero afecten algo de lo que depende el equipo del Director de Operaciones.
Por ejemplo, supongamos que la función calcularPago() y la función reportarHoras() comparten un algoritmo común para calcular las horas no extras. Supongamos también que los desarrolladores, que tienen cuidado de no duplicar código, ponen ese algoritmo en una función llamada horasRegulares().
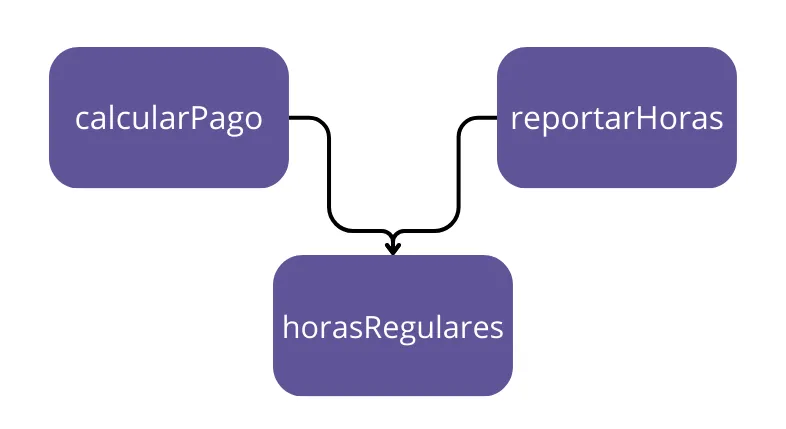
Ahora supongamos que el equipo del Director Financiero decide que la forma en que se calculan las horas no extras necesita ser ajustada. En contraste, el equipo de RR.HH. del Director de Operaciones no quiere ese ajuste en particular porque usan las horas no extras para un propósito diferente.
Un desarrollador recibe la tarea de hacer el cambio y ve la conveniente función horasRegulares() llamada por el método calcularPago(). Desafortunadamente, ese desarrollador no se da cuenta de que la función también es llamada por la función reportarHoras().
El desarrollador hace el cambio requerido y lo prueba cuidadosamente. El equipo del Director Financiero valida que la nueva función funciona como se desea, y el sistema se implementa.
Por supuesto, el equipo del Director de Operaciones no sabe que esto está sucediendo. El personal de RR.HH. continúa usando los informes generados por la función reportarHoras(), pero ahora contienen números incorrectos. Eventualmente se descubre el problema, y el Director de Operaciones está furioso porque los datos erróneos han costado a su presupuesto millones de pesos.
Todos hemos visto cosas como esta suceder. Estos problemas ocurren porque ponemos código del que dependen diferentes actores en estrecha proximidad. El SRP dice que separemos el código del que dependen diferentes actores.
SÍNTOMA 2: FUSIONES
No es difícil imaginar que las fusiones serán comunes en archivos fuente que contienen muchos métodos diferentes. Esta situación es especialmente probable si esos métodos son responsables ante diferentes actores.
Por ejemplo, supongamos que el equipo de DBAs del Director de Tecnología decide que debe haber un simple cambio de esquema en la tabla Empleado de la base de datos. Supongamos también que el equipo de empleados de RR.HH. del Director de Operaciones decide que necesitan un cambio en el formato del informe de horas.
Dos desarrolladores diferentes, posiblemente de dos equipos diferentes, extraen la clase Empleado y comienzan a hacer cambios. Desafortunadamente, sus cambios colisionan. El resultado es una fusión.
Probablemente no hace falta decir que las fusiones son un tema complejo. Nuestras herramientas son bastante buenas hoy en día, pero ninguna herramienta puede manejar todos los casos de fusión. Al final, siempre hay riesgo.
En nuestro ejemplo, la fusión pone en riesgo tanto al Director de Tecnología como al Director de Operaciones. No es inconcebible que el Director Financiero también pueda verse afectado.
Hay muchos otros síntomas que podríamos investigar, pero todos implican que múltiples personas cambien el mismo archivo fuente por diferentes razones.
Una vez más, la manera de evitar este problema es separar el código que soporta a diferentes actores.
Algunas soluciones
Hay muchas soluciones diferentes para este problema. Cada una mueve las funciones a diferentes clases.
Quizás la forma más obvia de resolver el problema es separar los datos de las funciones. Las tres clases comparten acceso a DatosEmpleado, que es una estructura de datos simple sin métodos. Cada clase contiene solo el código fuente necesario para su función particular. No se permite que las tres clases se conozcan entre sí. Así se evita cualquier duplicación accidental.
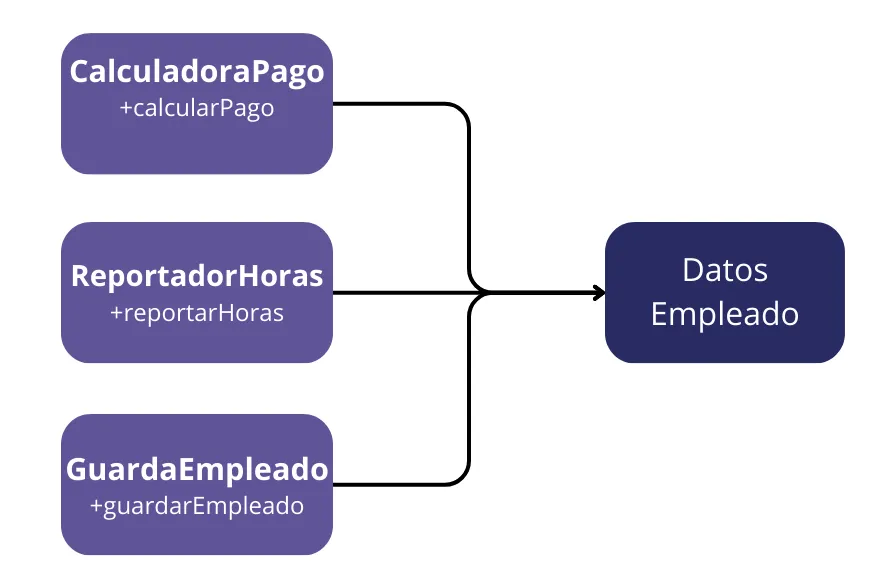
La desventaja de esta solución es que los desarrolladores ahora tienen tres clases que tienen que instanciar y rastrear. Una solución común a este dilema es usar el patrón Fachada.
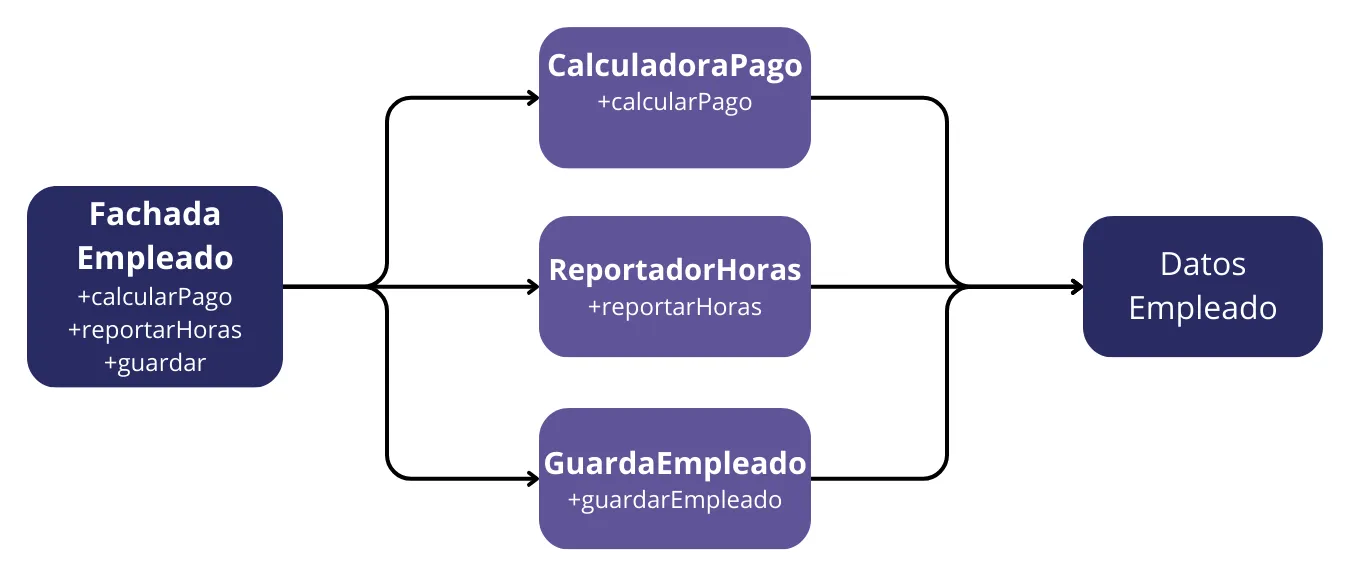
La FachadaEmpleado contiene muy poco código. Es responsable de instanciar y delegar a las clases con las funciones.
Algunos desarrolladores prefieren mantener las reglas de negocio más importantes más cerca de los datos. Esto se puede hacer manteniendo el método más importante en la clase Empleado original y luego usando esa clase como una Fachada para las funciones menores.
Podrían objetar estas soluciones basándote en que cada clase contendría solo una función. Este no es el caso. El número de funciones requeridas para calcular el pago, generar un informe o guardar los datos es probable que sea grande en cada caso. Cada una de esas clases tendría muchos métodos privados en ellas.
Cada una de las clases que contiene tal familia de métodos es un ámbito. Fuera de ese ámbito, nadie sabe que existen los miembros privados de la familia.
Conclusiones
El Principio de Responsabilidad Única trata sobre funciones y clases, pero reaparece en una forma diferente en dos niveles más. A nivel de componentes, se convierte en el Principio de Cierre Común (en inglés, Common Closure Principle). A nivel arquitectónico, se convierte en el Eje de Cambio responsable de la creación de Límites Arquitectónicos.